Its very important to learn hadoop by pracitce.
One of the learning curve is how to write first map reduce app and debug in favorite IDE Eclipse? Do we need any Eclipse plugins? No, we do not. We can do haooop development without map reduce plugins
This tutorial will show you how to setup eclipse and run you map reduce project and MapReduce job right from IDE. Before you read further, you should have setup Hadoop single node cluster and your machine.
You can download the eclipse project from GitHub
Use Case:
We will explore the weather data to find maximum temperature from Tom White’s book Hadoop: Definitive Guide (3rd edition) Chapter 2 and run it using ToolRunner
I am using linux mint 15 on VirtualBox VM instance.
In addition,you should have
- Hadoop (MRV1 am using 1.2.1) Single Node Cluster Installed and Running, If you have not done so, would strongly recommend you do it from here
- Download Eclipse IDE, as of writing this, latest version of Eclipse is Kepler
1.Create New Java Project
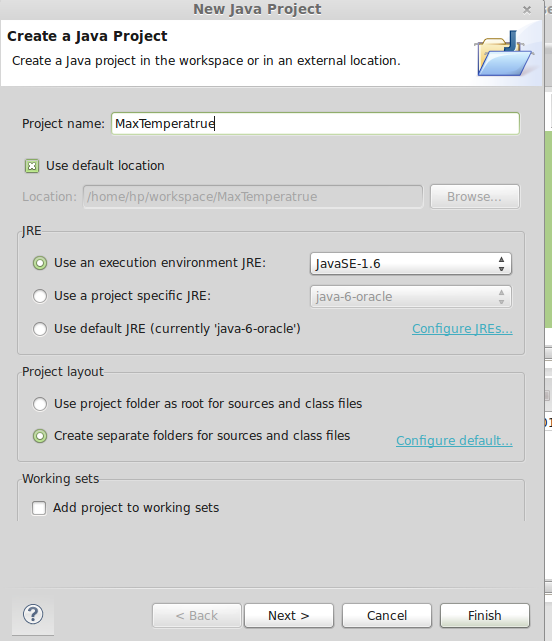
2.Add Dependencies JARs
Right click on project properties and select Java build path
add all jars from $HADOOP_HOME/lib and $HADOOP_HOME (where hadoop core and tools jar lives)


3. Create Mapper
package com.letsdobigdata;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxTemperatureMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+') { // parseInt doesn't like leading plus
// signs
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
4. Create Reducer
package com.letsdobigdata;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTemperatureReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
5. Create Driver for MapReduce Job
Map Reduce job is executed by useful hadoop utility class ToolRunner
package com.letsdobigdata;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/*This class is responsible for running map reduce job*/
public class MaxTemperatureDriver extends Configured implements Tool{
public int run(String[] args) throws Exception
{
if(args.length !=2) {
System.err.println("Usage: MaxTemperatureDriver <input path> <outputpath>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperatureDriver.class);
job.setJobName("Max Temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0:1);
boolean success = job.waitForCompletion(true);
return success ? 0 : 1;
}
public static void main(String[] args) throws Exception {
MaxTemperatureDriver driver = new MaxTemperatureDriver();
int exitCode = ToolRunner.run(driver, args);
System.exit(exitCode);
}
}
6. Supply Input and Output
We need to supply input file that will be used during Map phase and the final output will be generated in output directory by Reduct task. Edit Run Configuration and supply command line arguments. sample.txt reside in the project root. Your project explorer should contain following

 ]
]
7.Map Reduce Job Execution

8. Final Output
If you managed to come this far, Once the job is complete, it will create output directory with _SUCCESS and part_nnnnn , double click to view it in eclipse editor and you will see we have supplied 5 rows of weather data (downloaded from NCDC weather) and we wanted to find out the maximum temperature in a given year from input file and the output will contain 2 rows with max temperature in (Centigrade) for each supplied year
1949 111 (11.1 C)
1950 22 (2.2 C)

Make sure you delete the output directory next time running your application else you will get an error from Hadoop saying directory already exists.
Happy Hadooping!

Thanks so much for this helpful tutorial!
Thanks lagvinoles for reading my post and glad you find it helpful!
Hey! I followed the steps but it didn’t seems to be working! I guess I have messed it up somewhere. While writing the code, the import statement is not listing the classes under org.apache.hadoop.io.*
I have configured Hadoop 2.2.0 on my system.
Thanks in advance for your help!
Please check hadoop 2.2.0 api reference, its possible some stuff may have moved around from 1.2.0, hope this helps
http://hadoop.apache.org/docs/current2/api/
I liked this article so much, it was very useful,
thanks!
Thanks and glad you find it useful!
Hi, I follow these steps in this article and everything seem pretty good. But I find that every time I run the job in eclipse, jobid seems to be a little bad. jobid: job_local_0001, and I cannot find the job info on http://master:9001.
Hi Jeff,
Thanks for reaching this far
Are you able to check job status using ?
$HADOOP_HOME/bin/hadoop job -status job_xxx
Thanks,
Hardik
Thanks for your kindly reply. I have tried to run hadoop command to check job status and receive the message “Could not find job job_local_0001”. I also check the log file and there is no log file related to my job. It seems like the job does not run on the cluster. But, when I make a jar file and use $HADOOP_HOME/bin hadoop jar command , I can find job info through http://master:9001 and jobid seems to be normal.
i am not getting DFS location ,i am getting error like localhost/127.0.0.1 failed on connection exception :java.net.ConnectionException :connection refused:no further information …..
i blocked windows firewall also still i am getting error please help me..
THANKS IN ADVANCE
Hi Ramesh,
Thanks for going over this
Whats your core-site.xml looks like
Usually it would be something like below
fs.default.name
hdfs://localhost:9000
The name of the default file system.
also make sure your namenode is formatted and you can start your namenode on you local machine
Thanks,
Hardik
I think I’m missing something fundamental here wrt running jobs in hadoop/hdfs vs eclipse. I’m running this example and WordCount on Hadoop 2.2
When I run a mapper/reducer it always looks for the input/output on the hdfs file system, though you seem to be using eclipse local files/dirs. Similarly it seems to want my java class to exist in a jar on the hadoop classpath. ie hadoop can’t ‘see’ the mapper/reducer classes at runtime when running from eclipse, only when I run as command line : “hadoop jar jarname.jar javaclassname /inputdir /outputdir”. Any insights are appreciated
Hi Sean,
Yes, I have used the local filesystem to run the example
you can set the fs.default.name to hdfs for e.g
Configuration conf = getConf();
conf.set(“fs.default.name”, “hdfs:///localhost.localdomain:8020/”);
you can package your map reduce program in jar and add it to the CLASSPATH for e.g
export HADOOP_CLASSPATH=hadoop-examples.jar
% hadoop MaxTemperature input/ncdc/sample.txt output where MaxTemperature is the name of driver class (has main() method)
Thanks,
Hardik
Thanks Hardik. This does however seem a little tedious to have to jar up each time you change and run a MR class. How does one quickly develop and unit test a new MR class?
Yes, you are right. Ideally you could use maven project to quickly take care of deployment logistics and unit test your code
Thanks so much. I could setup my Eclipse finally to run/test the MR jobs.
hai thanks for excellent job.
Hadoop Training in Chennai
Thanks so much.i have learn to lot of hadoop.
Hadoop Training in Chennai
I have hadoop 2.2 in my system. i get an exception like
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.mindtree.hadoopstuff.MyMapper1 not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:1895)
at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:186)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:722)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:340)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:167)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1548)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:162)
Caused by: java.lang.ClassNotFoundException: Class com.mindtree.hadoopstuff.MyMapper1 not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:1801)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:1893)
… 8 more
whereas i have the mapper class in the project. i even tried by adding mapper nad reducer as a runnable jar, but i get same exception.
Thanks in advance
i dont have idea about what type of input text file has been given as argument.. help me if you have any idea releted this exception / error.
Exception in thread “main” java.lang.VerifyError: Bad type on operand stack
Exception Details:
Location:
org/apache/hadoop/mapred/JobTrackerInstrumentation.create(Lorg/apache/hadoop/mapred/JobTracker;Lorg/apache/hadoop/mapred/JobConf;)Lorg/apache/hadoop/mapred/JobTrackerInstrumentation; @5: invokestatic
Reason:
Type ‘org/apache/hadoop/metrics2/lib/DefaultMetricsSystem’ (current frame, stack[2]) is not assignable to ‘org/apache/hadoop/metrics2/MetricsSystem’
Current Frame:
bci: @5
flags: { }
locals: { ‘org/apache/hadoop/mapred/JobTracker’, ‘org/apache/hadoop/mapred/JobConf’ }
stack: { ‘org/apache/hadoop/mapred/JobTracker’, ‘org/apache/hadoop/mapred/JobConf’, ‘org/apache/hadoop/metrics2/lib/DefaultMetricsSystem’ }
Bytecode:
0000000: 2a2b b200 03b8 0004 b0
at org.apache.hadoop.mapred.LocalJobRunner.(LocalJobRunner.java:422)
at org.apache.hadoop.mapred.JobClient.init(JobClient.java:488)
at org.apache.hadoop.mapred.JobClient.(JobClient.java:473)
at org.apache.hadoop.mapreduce.Job$1.run(Job.java:513)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614)
at org.apache.hadoop.mapreduce.Job.connect(Job.java:511)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:499)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:530)
at com.letsdobigdata.MaxTemperatureDriver.run(MaxTemperatureDriver.java:35)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:84)
at com.letsdobigdata.MaxTemperatureDriver.main(MaxTemperatureDriver.java:41)
looks like you are using older version of hadoop possibly prior to hadoop 1.1 – googling the error gives me this http://examples.javacodegeeks.com/java-basics/exceptions/java-lang-verifyerror-how-to-solve-verifyerror/
i am getting an exception string out of range exception in mapper class map function: 19
can we run the same program using hadoop commands in terminal?
You can package your MapReduce program in jar and run from hadoop/bin directory – folllowing is straight from hadoop documentation
jar
Runs a jar file. Users can bundle their Map Reduce code in a jar file and execute it using this command.
Usage: hadoop jar [mainClass] args…
Hi, Can you please provide sample “sample.txt” input data file. Since I have no clue what data to be passed in this example. I am new to hadoop and trying out some sample programs to run. Thanks in advance.
-Mayank
You can find it here > https://github.com/tomwhite/hadoop-book/
good explanation. will it be always local job when run in eclipse even with arguments pointing to hdfs like hdfs://localhost:9000/input.txt hdfs://localhost:9000/output? I couldnt find this availble in Resource manager or job history when directly run in eclipse than exporting as jar and running in terminal..
hello can anyone tell me how do i get jars files?? for this project
hey please can anyone help me on this i get a error saying, can anyone help me resolving this
Exception in thread “main” java.lang.NoSuchMethodError: org.apache.commons.cli.OptionBuilder.withArgPattern(Ljava/lang/String;I)Lorg/apache/commons/cli/OptionBuilder;
at org.apache.hadoop.util.GenericOptionsParser.buildGeneralOptions(GenericOptionsParser.java:181)
at org.apache.hadoop.util.GenericOptionsParser.parseGeneralOptions(GenericOptionsParser.java:341)
at org.apache.hadoop.util.GenericOptionsParser.(GenericOptionsParser.java:136)
at org.apache.hadoop.util.GenericOptionsParser.(GenericOptionsParser.java:121)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:59)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:79)
at com.letsdobigdata.MaxTemperatureDriver.main(MaxTemperatureDriver.java:46)
Thank you very much, this tutorial really help me :))
Thanks a lot It help me lot ..keep updating
thanks a lot really help full